எழுத்தைக் காப்போம்! இனத்தைக் காப்போம்! – 1 – இலக்குவனார் திருவள்ளுவன்

தமிழைப் பாதுகாப்பதாகவும் பரப்புவதாகவும் கூறிக் கொண்டு சிலர் கங்கணம் கட்டிக் கொண்டு பொய் மூட்டைகளை அவிழ்த்துவிட்டு எழுத்துச் சிதைவு முயற்சிகளில் ஈடுபட்டு வருகின்றனர். உண்மையில் பிற அனைத்து மொழிகளுடனும் ஒப்பிடுகையில் மிகச் சிறந்ததாயும் அறிவியல் முறையில் அமைந்ததாயும் உள்ள ஒரே வடிவப் பாங்கு தமிழ் மொழிக்குரிய வரி வடிவ அமைப்பாகும். இவ்வுண்மையைப் புரிந்து கொள்ளாத சிலர் தாங்களும் குழம்பிப் பிறரையும் குழப்பும் முயற்சியில் ஈடுபட்டு வருகின்றனர். இத்தகையோர் மிகச் சிலராய் இருப்பினும் இவர்கள் செல்வாக்கு உள்ள இடங்களில் உள்ளமையாலும் திரும்பத் திரும்பக் கூறியதையே கூறி உண்மையாக இருக்குமோ எனப் பிறரை ஐயப் படுகுழியில் தள்ளப் பார்ப்பதாலும் நாம் மறுக்க வேண்டிய கட்டாயத்தில் உள்ளோம். அந்த வகையில் தமிழ் வரிவடிவச் சீர்மையையும் சீர்திருத்தம் என்ற பெயரில் மேற்கொள்ளும் சிதைவு முயற்சிகளுக்கு முற்றுப்புள்ளி வைக்க வேண்டியதன் தேவையையும் நாம் காணலாம்.
குறைபாடுள்ள ஒன்றைத் திருத்துவதே முறையானது. மாறாகச் சீராக உள்ளதைத் திருத்துவது என்பது சீரழிப்பே ஆகும். அந்த வகையில் சீராக உள்ள தமிழ் வரிவடிவங்களில் சிதைவு ஏற்படுத்த வலியுறுத்துபவர்களில் குறிப்பிடத் தகுந்தவர் எளிய கவிதைகள் மூலம் தமிழன்னையை அழகுபடுத்தும் அறிஞர் வா.செ.குழந்தைசாமி ஆவார். அவர் குறிப்பிடும் கருத்துகளில் முதன்மையானவை தமிழ் எழுத்துகளின் எண்ணிக்கை மிகுதியாக உள்ளதாலும் உயிர் மெய்க் குறியீடுகள் சீராக அமையாமையாலும் படிக்க முடியாமல் போகின்றது என்பதாகும். உண்மையில் தமிழ் எழுத்துகளில் உயிர் மெய்க் குறியீடுகள் என்பன அட்டவணை 1 இல் குறிப்பிட்டாற்போன்று கால், பிறை, விலங்கு, கீற்று, கொம்பு என ஐந்தாகும். இவற்றுள் கொம்பும் காலும் இணைந்த கொம்புக்கால் என்பது ஊகாரத்திலும் ஔகாரத்திலும் பயன்படுத்தப்படுகின்றது. இது ள என்னும் எழுத்து போன்று இருந்தாலும் (கொம்பும் காலும் இணைந்த) தனிக் குறியீடு என்பதால் அட்டவணை 1 இல் தனியாகக் காட்டப்பட்டுள்ளது.

ஐந்து உயிர் மெய்க் குறியீடுகளே அட்டவணை இரண்டில் குறிப்பிட்டாற்போன்று எழுத்துடன் இணைந்தும் முன்னால் அல்லது பின்னால் அல்லது முன்னும் பின்னுமாகச் சேர்ந்தும் பதினெட்டு வகையாகக் காட்சியளிக்கின்றன.
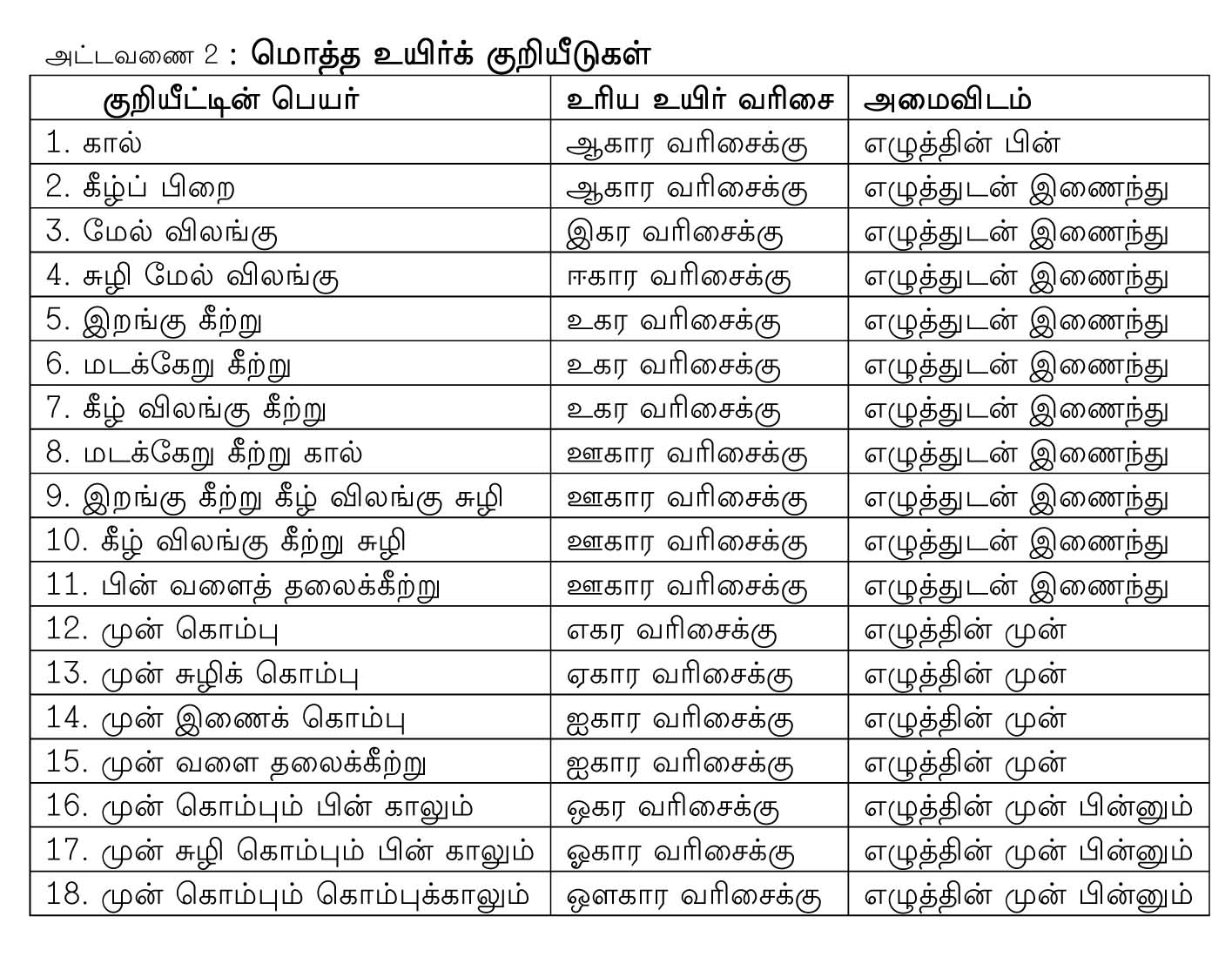
இவற்றுடன் மெய்யெழுத்தில் உள்ள புள்ளி நீக்கப்படுவதன் மூலம் உயிர்மெய் அகரம் உருவாகிறது. எனவே, உயிர்மெய் அமையும் வகை பத்தொன்பது என்று கொள்ளலாம். இவற்றை அட்டவணை 3 அ, அட்டவணை 3 ஆ, அட்டவணை 3 இ ஆகியவை விளக்குகின்றன.
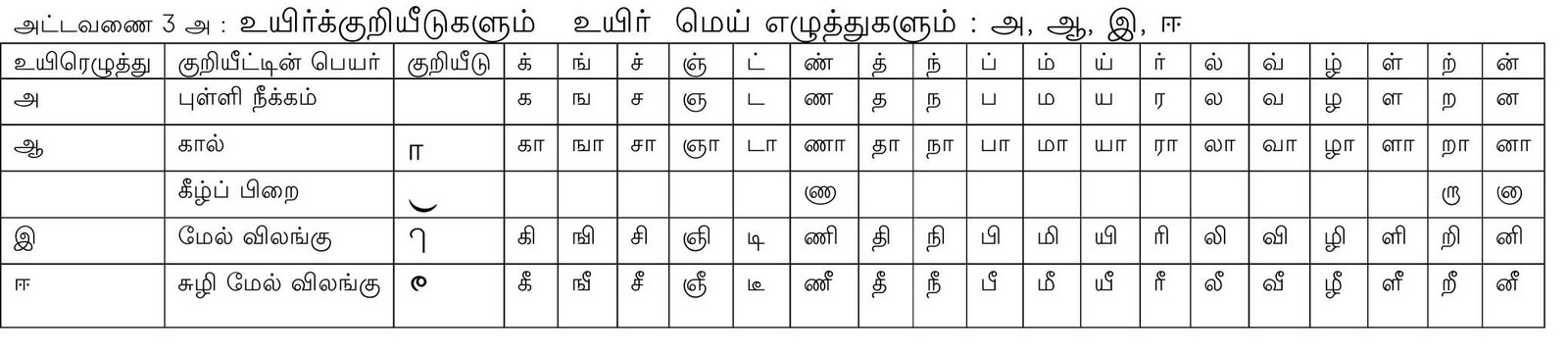

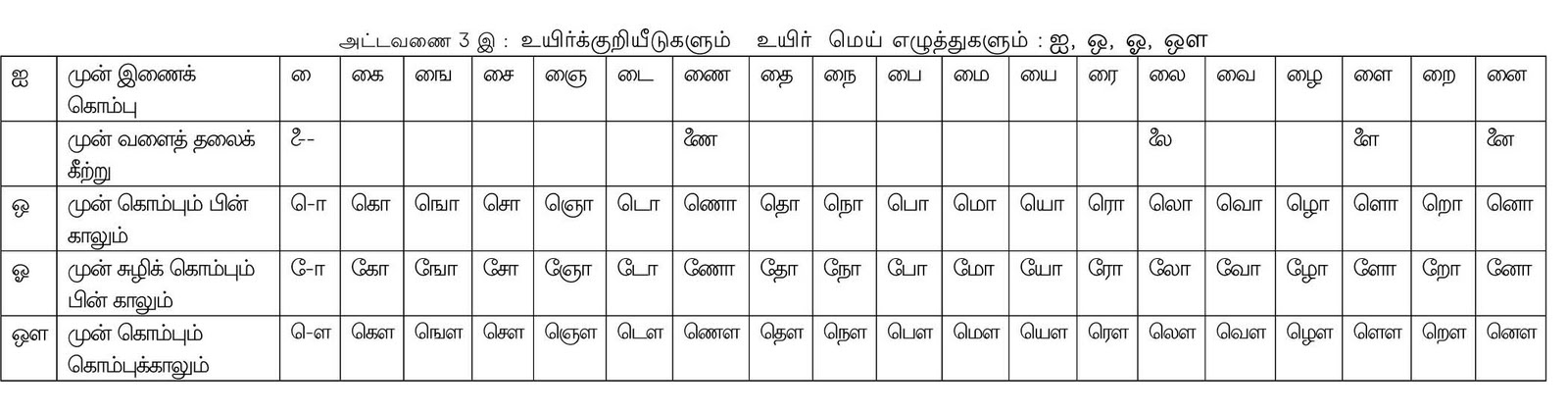
இவற்றுள் ணா, றா, னா ஆகியவை மிக மிகத் தொடக்கக்காலத்தில் இவ்வாறேதான் எழுதப்பட்டு வந்துள்ளன. இவற்றைக் கவிமணி தேசிகவிநாயகம் பிள்ளை அவர்களும் குறிப்பிட்டுள்ளார். மதுரை காமராசர் பல்கலைக்கழகம் வெளியிட்டுள்ள கலைச்சொல் அகர முதலியிலும் ஆறாயிரம் எனத் துணைக்காலுடன் கல்வெட்டில் எழுதப்பட்டுள்ளது குறிக்கப் பெற்றுள்ளது. பின்னரே எழுதும்பொழுது ஏற்படும் குழப்பத்தைத் தவிர்ப்பதற்காகப் பிறை என்னும் வடிவமிட்டு எழுதியுள்ளனர். முன்பே இவ்வாறு மாற்றத்தை ஏற்றுக் கொண்டுள்ளது போல் இப்போது ஏற்றுக் கொண்டால் என்ன என்று சிலர் வினவலாம். குறியீடுகளை அறிவியல் முறையில் அமைக்கும் பொழுதே எழுதும் முறைக்கு முதன்மை கொடுத்து இவ்வாறு அமைத்துள்ளனர். ஆனால் கல்வெட்டுகளில் பெரியார் எழுத்து என்று இப்பொழுது நாம் சொல்லும் இந்த முறையைப் பின்பற்றியுள்ளனர். இவைபோல்தான் ணை, லை, ளை, னை ஆகியன எழுதுகையில் ஏற்படும் எழுத்து மயக்கத்தை அல்லது குழப்பத்தைப் போக்குவதற்காக துதிக்கை எழுத்து என்று இப்போது அறியாமல் அழைக்கப்படுகின்ற முன்வளைத் தலைகீற்று பயன்படுத்தப்பட்டது. இதனால் சுழிகளாக இணைந்து வருகையில் ஏற்படும் ஐயப்பாடு நீங்கியது. டி, டீ ஆகிய எழுத்துகள் உள்ளவாறே மேல் விலங்கு இடப்பட்டால் பி, பீ என்ற எழுத்து போல் தோன்றும் என்பதால் சற்று உள்வாங்கிக் குறியீடுகள் போடப்பட்டுள்ளமை போல்தான் மேலே குறிப்பிட்ட சில ஆகார ஐகாரக் குறியீடுகள் அறிவியல் முறையில் எழுதப்படுவதற்கு வாகாக அமைந்துள்ளன. இவற்றை அறியாமல் நாம் 1978 ஆம் ஆண்டு கொண்டு வந்த எழுத்துச் சீர்திருத்தம் தேவையற்றதாகும். எனவே, மீண்டும் பழைய முறையை நடைமுறைப்படுத்துவதே சிறந்ததாகும்.
அடிப்படையில் அனைவரும் தவறாக எண்ணிவரும் உகரக் குறியீடுகள் அனைத்தும் அறிவியல் முறையில் மிகச் செம்மையாக அமைந்துள்ளன என அட்டவணை நான்கைப் பார்த்தால் புரிந்து கொள்ளலாம். உகரக் குறியீட்டின் பொதுப்பெயர் கீற்று என்பதாகும். எழுத்து முடியும் இடத்திற்கேற்ப இதனைத் தொடர்ந்து குறிப்பிடும் வகையில் உகர உயிர்மெய் எழுத்துகள் அமைந்துள்ளன. எடுத்துக்காட்டாகச் சொல்ல வேண்டும் என்றால், க என்னும் எழுத்துடன் கீற்றைக் (க+|)குறிப்பிடுகையில் த என்ற குழப்பம் வரக் கூடாது என்பதற்காகக் கீழ் விலங்குக் கீற்றாக ( ) அமைத்துள்ளனர்; த என்னும் எழுத்தில் முடியும் இடத்தில் கீற்றைக் குறிப்பிடுகையில் த எழுத்தில் இருந்து வேறுபடுத்த முடியாது என்பதால் மடக்கேறு கீற்றாகப் பயன்படுத்தியுள்ளனர். இவ்வடிப்படையில்தான் ஊகாரக் குறியீடுகளும் நேர்த்தியாயும் எழுதுவதற்கு வாகாகச் சீரியதாயும் அமைந்துள்ளன.
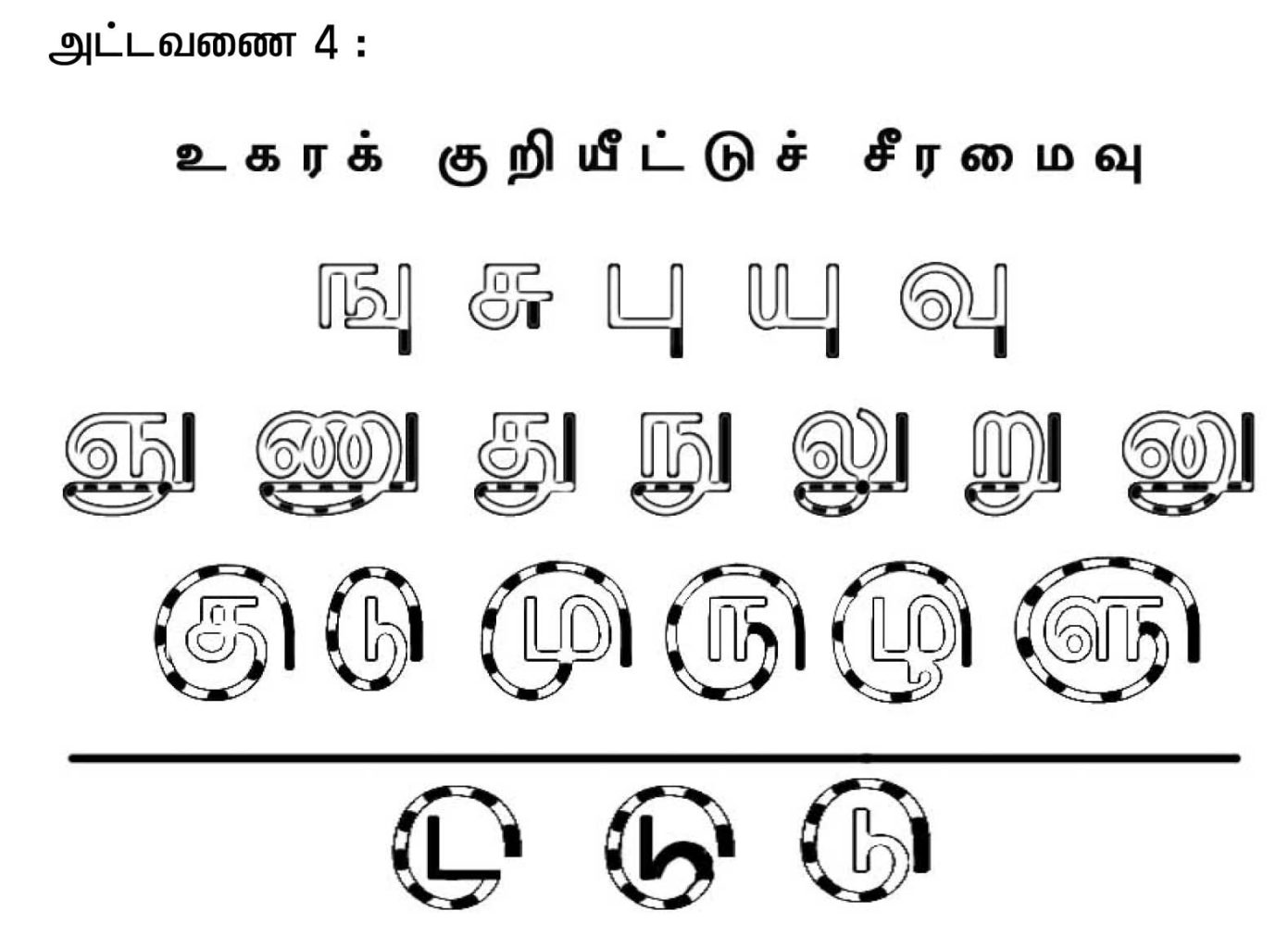
(காப்பு தொடரும்)
– இலக்குவனார் திருவள்ளுவன்



ஐயா,
தங்களுடைய கருத்தை முழுமையாக ஏற்றுக்கொள்ள இயலவில்லை.
தற்போதய காலக்கட்டத்தில் உயிர்க்குறியீடுகளை சீரமைத்து அனைத்து உயிர்மெய் எழுத்துகளும் சீரான ஓருருவாக இருத்தல் அவசியம்.
இப்பூவுலகை, ஏன் இந்த அண்டத்தையே மூன்று வகைக்குள் அடக்கலாம். அவை:
(1) உயிர்கள்,
(2) உயிரில்லாப் பொருட்கள்,
(3) உயிருள்ள பொருட்கள்.
அது போல் உலகில் உள்ள மொழிகளை, மூன்றாக வகைப்படுத்தலாம். அவை:
(1) குறை இயற்கை மொழிகள். (Below Natural Languages). அதாவது, உயிர் எழுத்து, மெய் எழுத்து மட்டும் உள்ளவை, (உதாரணம்: ஆங்கிலம்)
(2) இயற்கை மொழிகள். (Natural Language). அதாவது, உயிர் எழுத்து, மெய் எழுத்துடன், உயிர்மெய் எழுத்து மட்டும் உள்ளவை, (உதாரணம்: தமிழ்)
(3) செயற்கை மொழிகள். (Unnatural Languages) அதாவது, உயிர் எழுத்து, மெய் எழுத்து, உயிர்மெய் எழுத்துடன், ஒட்டு எழுத்து, கூட்டு எழுத்து போன்று உள்ளவை (உதாரணம்: மலையாளம்) மற்றும் எழுத்துகளே இல்லாமல் கருத்துப் படங்கள் மட்டும் உள்ள மொழிகள் (உதாரணம்: சீனம்)
எனக்குத் தெரிந்த வரை, இப்பூவுலகில், தமிழ் மட்டுமே இயற்கை மொழியாகத் (Natural Language) திகழ்கிறது எனலாம்.
தமிழ் உயிர்க்குறியீடு சீர்திருத்தம்
எனினும், தமிழ் எழுத்துகள் சிலபல சீரற்றதாக அமைந்துள்ளன. அவற்றை சீர்திருத்துவது அவசியம். உடம்புடன் உயிர் சேரும்போது உடம்பு ஈருருவாக, மூவுருவாக மாறுவதில்லை. அதுபோல் மெய் (எழுத்தும்) உயிருடன் (எழுத்துடன்) சேரும் போது ஓர் எழுத்தாக தொல்காப்பியர் மற்றும் திருவள்ளுவர் காலங்களில் இருந்தன. தற்போதுள்ள தமிழ் எழுத்துகள் பல்லவர் காலத்தில் ஈருவாகவும் மூவுருவாகவும் சீரற்ற ஓருருவாகவும் மாறி அமைந்துவிட்டன.
தற்போது தட்டச்சு இயந்திரம் காலாவதி ஆகிவிட்டதாலும் உயிர்ச் சின்னங்களை கணினியில் பொருத்துவதில் சிக்கல் இருப்பதாலும் அதனால் கணியத்திறன் ஆங்கிலம் போன்று இல்லாததாலும் தமிழ் எழுத்துகளை ஓருருவாக மீண்டும் மாற்றிட வேண்டிய கட்டாயம் ஏற்பட்டுள்ளது.
ஓருருவாக்குதல்
அதற்கு, “ஆ” முதல் “ஔ” வரை உள்ள உயிர்ச் சின்னங்களை மெய்யின் மீது புள்ளி இருக்கும் இடத்தில் அமைத்தால் உயிர்மெய்கள் சீரான ஓருருவாக அமைந்துவிடும். மேலும், ஊ, ஔ ஆகிய இரண்டு உயிர் எழுத்துகள் ஈருருவாக உள்ளன. அவைகளையும் ஓருருவாக மாற்றி அமைத்தால் நல்லது.
“ஹ” எனும் எழுத்து மிகவும் பெரியதாக உள்ளது. இதற்குப் பதில் “௪” எனும் எழுத்தைப் பயன்படுத்தலாம்.
“ட” எனும் எழுத்து சமச்சீராக இல்லை. இந்த எழுத்தில் உள்ள செங்குத்துக் கோட்டை மையத்திற்கு நகர்த்தினால் தலைகீழ் “T” ஆக மாறி இருக்கும். அந்த தலைகீழ் “T” – யை “ட” எனும் எழுத்துக்குப் பதிலாக பயன்படுத்தலாம்.
இதனால், தமிழ் எழுத்துகள் ஓருருவாக அமைவதோடு தற்போது கணினியில் உயிர்ச் சின்னத்தை இருத்தும் போது ஏற்படும் குறைபாடுகளும் நீங்கிவிடும்.
“ஆ” முதல் “ஔ” வரை புதிய உயிர்ச் சின்னங்கள் கீழே தரப்பட்டுள்ளன:
(1) ஆ (AA) – கிடைக்கோடு
(2) இ (I) – முன்சாய்வுக்கோடு
(3) ஈ (II) – முன்சாய்வுக் கோட்டின் முடிவில் சுழி
(4) உ (U) – பின்சாய்வுககோடு
(5) ஊ (UU) – பின்சாய்வுக் கோட்டின் முடிவில் சுழி
(6) எ (E) – கிடைக்கோட்டின் மேல் இடப்பக்கமாக சுழியும்
(7) ஏ (EE) – கிடைக்கோட்டின் மேல் வலப்பக்கமாக சுழியும்
(8) ஐ (AI) – கிடைக்கோட்டின் மேல் இருபக்கமும் சுழி
(9) ஒ (O) – கிடைக்கோட்டின் கீழ் இடப்பக்கமாக சுழி
(10) ஓ (OO) – கிடைக்கோட்டின் கீழ் வலப்பக்கமாக சுழி
(11) ஔ (AU) – கிடைக் கோட்டின் கீழ் இருபக்கம் சுழி.
1. Hyphen for ஆ (AA),
2. Forward Hyphen for இ (I),
3. Forward Hyphen with a ring at top for ஈ (II)
4. Backward Hyphen for உ (U),
5. Backward Hyphen with a ring at top for ஊ (UU),
6. Left end ring ABOVE Hyphen for எ (E),
7. Right end ring ABOVE Hyphen for ஏ (EE),
8. Both end ring ABOVE Hyphen for ஐ (AI),
9. Left end ring BELOW Hyphen for ஒ (O),
10. Right end ring BELOW Hyphen for ஓ (OO),
11. Both end ring BELOW Hyphen for ஔ (AU)
எல்லா தமிழ் எழுத்துகளும் ஓரெழுத்தாக சீர்திருத்த குறைந்தது 50 ஆண்டு கால இடை வெளியில் நீண்ட காலத் திட்டமாக நிறைவேற்ற தங்களது ஒத்துழைப்பை நாடுகின்றென்.
ஒருங்குறியில் தமிழ் உட்பட இந்திய மொழிகள் – சிக்கல்கள் மற்றும் தீர்வுகள்
அன்றைய பழந்தமிழும் இன்றைய இந்திய மொழிகளும்
ஆதி காலத்தில், இந்தியத் துணைக் கண்டம் முழுவதும் ‘பழந்தமிழ்’ வழங்கி வந்த போது, ஆரியர்கள் ஊடுருவினார்கள் ஆண்டார்கள் சென்றார்கள்.
அவர்கள் சென்ற பிறகும் இங்குள்ள சிலபலர், வட இந்தியாவில் வெளி நாட்டு ஆரிய மொழியை முன்னிருத்தியதால், ‘பழந்தமிழ்’ மொழி திரிந்து திரிந்து கிளைத்து கிளைத்து தற்போதுள்ள இந்தி முதலிய வட நாட்டு மொழிகளாயின.
தென்னாட்டவர்கள் வெளி நாட்டு ஆரிய மொழியான சமஸ்கிருதத்திற்கு வட மொழி என அடைமொழி கொடுத்தனர்.
அப்போது தென்னாட்டில் பழந்தமிழ் சங்கத் தமிழாக மேம்பாடு அடைந்து தென் மொழி என்று அழைக்கப்பட்டது.
பிறகு, இங்குள்ள சிலபலர், தென் இந்தியாவிலும் வjட மொழியாகிய வெளி நாட்டு ஆரிய மொழியை முன்னிருத்தியதால், சங்கத் தமிழ் பிரிந்து கிளைத்து தற்போதுள்ள கன்னடம் முதலிய தென்னிந்திய மொழிகளாயின.
இதற்கு ஆதாரம்: பழந்தமிழின் வாக்கிய அமைப்புதான் இன்று வட இந்திய, தென் இந்திய மொழிகள் யாவும் கொண்டுள்ளன.
அதன் பிறகு, இந்தியத் துணைக் கண்டத்தில், ஆங்கிலேயர்கள் வந்தார்கள், ஆண்டார்கள் சென்றார்கள்.
அவர்கள் சென்ற பிறகும், அவர்களின் சூழ்ச்சியால் இங்குள்ளவர்கள் ஆங்கிலத்தை முன்னிருத்துவதால், தமிழ் உட்பட இந்திய மொழிகள் இன்னும் பின்தங்கியுள்ளன.
இந்தியாவிற்கு சுதந்திரம் கிடைத்தது; ஆனால், இந்திய மொழிகளுக்கு இன்னும் சுதந்திரம் கிடைக்கவில்லை.
தமிழ் முதலிய இந்திய மொழிகளுக்கு சுதந்திரம் கிடைக்க, மாநில ஆட்சி மொழிகள் யாவும், இந்திய அரசின் ஆட்சி மொழியாக, அந்தந்த மாநில மொழி அந்தந்த மாநில அரசின் கல்வி மொழியாக, நீதிமன்ற மொழியாக முன்நிற்க வேண்டும்
ஒருங்குறியும் குறியாக்கமும்
அதற்கு, அனைத்து எழுத்துகளுக்கும் ஒருங்குறியில் (Unicode) குறியிடங்கள் (Code Points) பெற்று தமிழ் உட்பட இந்திய மொழிகள் ஆங்கிலம் போன்று முழு அளவில் கணித்திறன் பெற்றிருக்க வேண்டும்.
அதற்கான, முயற்சியில் தமிழர்களும் இந்தியர்களும் இப்போது ஈடுபட வேண்டும்.
ஒருங்குறி தொடங்கிய போது, ஒரே ஒரு தளம் (Plane) மட்டுமே இருந்தது. அதில், 65,536 (2^16) குறியிடங்கள் (code points) மட்டுமே இருந்தன.
தற்போது, 17 தளங்கள் உள்ளன. பிஎம்பீ (BMP) எனும் முதல் தளத்தில் அனைத்து குறியிடங்களும் நிரம்பிவிட்டன.
மீதமுள்ள தளங்களில் 16, 17வது தளங்கள் தனிப்பயன் பகுதிக்கு ஒதுக்கப் பட்டுள்ளது. 11 தளங்கள்
காலியாகவே உள்ளன.
ஒருங்குறி ஒன்றியம் (Unicode Consortium) தொடங்கியபோது ஆஸ்க்கி (ASCII) போன்று குறியிட எண்ணே (Code Point) குறியாக்க எண்ணாகவும் (Encoding Point) இருந்தது. பிஎம்பீ (BMP) ல் 16 பிட் குறியிட எண்ணும் 16 பிட் குறியாக்க எண்ணும் ஒன்றாக இருந்தது.
ஐஈஈஈ (IEEE) நிறுவனம் 31 பிட் வரை தளங்களை உருவாக்கிய பிறகு அடுத்தடுத்த தளங்களில் 17 பிட், 18 பிட் என்று 31 பிட் வரை கூடிக் கொண்டு இருந்ததால் குறியிட எண்ணை குறியாக்க எண்ணாகவும் கொள்ள இயலவில்லை. ஒருங்குறி ஒன்றியம் மூன்று குறியாக்க முறைகளை அறிமுகம் செய்தது. அவை: (1) யூடிஎப்-8 (UTF-8), (2) யூடிஎப்-16 (UTF-16), (யூடிஎப்-32 (UTF-32) ஆகும்.
யூடிஎப்-8 ல் 8 பிட் அலகும், யூடிஎப்-16 ல் 16 பிட் அலகும், யூடிஎப்-32 ல் 32 பிட் அலகும் குறியாக்க அலகாக இருக்கின்றன.
யூடிஎப்-16 ல், பிஎம்பீ ல் மட்டும் குறியிட எண்ணும் குறியாக்க எண்ணும் ஒன்றாகவே உள்ளது. 0000 முதல் FFFF வரை ஒரு 16 பிட் அலகாக உள்ளது. தளம்-2 முதல் சரோகேட் இணை தேவைப்படுகின்றது. அதாவது 10000 முதல் 10FFFF வரை இரண்டு 16 பிட் அலகு தேவைப்படுகிறது.
(1) முதலாவது முதன்மைச் சிக்கல்: அடாமிக் (பிரிக்க இயலாத) எழுத்துக்கு மட்டுமே குறியிடம் ஒதுக்கும் கொள்கை.
ஒருங்குறி ஒன்றியம் பிரிக்க இயலாத (Atomic) எழுத்துக்கு மட்டுமே குறியிடம் ஒதுக்கப்படும் என்றும் பிற எழுத்துகளுக்கு அதாவது உயிர்மெய், கூட்டு எழுத்து ஒட்டு எழுத்து போன்றவற்றிற்கு குறியிடம் ஒதுக்கப்படாது என்றும் ஒரு கொள்கையை கடைபிடித்து வருகிறது. அதனால் தமிழ் முதலிய இந்திய மொழிகளில் உள்ள அனைத்து எழுத்துகளுக்கும் குறியிடம் ஒதுக்கப்படவில்லை.
உயிர் மெய் போன்ற பிற எழுத்துகள் ஒவ்வொன்றையும் அக்கு வேறு ஆணி வேறாகப் பிரித்து அதாவது புள்ளி இல்லா மெய்யைத் தனியாவும் புள்ளியைத் தனியாகவும் உயிர்க் குறியீட்டைத் தனித்தனியாகவும் குறியாக்கம் செய்து நிரல் வழி இணைக்க வேண்டும் என்று ஒருங்குறி ஒன்றியம் அறிவுரை வழங்கியுள்ளது. இதனால், குறியாக்க நினைவகம் ஒவ்வொரு குறியாக்க முறையிலும் மூன்று மடங்கு அதிகமாகிறது. அத்துடன் கணித்திறனும் ஆங்கிலம் போன்று முழுமையாக இல்லை.
(2) இரண்டாவது முதன்மைச் சிக்கல்: யூடிஎப்-16 (UTF-16) உள்ள சிக்கல்
சரோகேட் இணை, தளம் – 17 க்கு மேல் பெற இயலாது. அதனால், மூன்று வகை குறியாக்க முறையிலும் 18 வது தளம் முதல் அனைத்து கூடுதல் தளங்களும் முடக்கப்பட்டன. மேலும், யூடிஎப்-16 குறியாக்க முறையில் சோதனை மேற்கொண்டு பிழை நீக்கம் செய்யப்படாததால் குறியிடங்கள் வழக்கில் உள்ள மொழிகளுக்கு குறியிடங்கள் தளம் 2 முதல் தளம் 17 வரை ஒதுக்கப்படுவது இல்லை.
எனவே, அரிதாகப் பயன்படும் பழங்கால எழுத்துகளுக்கே குறியிடங்கள ஒதுக்கீடு செய்யப்படுகின்றன.
(3) யூடிஎப்-8 (UTF-8) அதிக குறியாக்க நினைவகம் தேவை
ஒருங்குறி ஒன்றியம் யூடிஎப்-8 குறியாக்கமுறையில் கீழ்க்காணுமாறு குறியாக்கம் செய்யப்படுகிறது:
(1) 00 – 7F > 0xxxxxxx > 1 octet
(2) 80 – 7FF > 110xxxxx, 10xxxxxx > 2 octet
(3) 800 – FFFF > 1110xxxx, 10xxxxxx, 10xxxxxx > 3 octet
(4) 10000 – 10FFFF > 11110xxx, 10xxxxxx, 10xxxxxx, 10xxxxxx, 4 octet
தமிழ் முதலிய இந்திய மொழிகளுக்கு உயிர், மெய் ஆகியவற்றை குறியாக்கம் செய்ய 8 பிட் கொண்ட 3 பைட் தேவை. ஆனால், உயிர்மெய் போன்ற எழுத்துகளுக்கு குறியிடம் ஒதுக்கப்படவில்லை. அதனால், மெய்யை தனியாகவும் புள்ளியைத் தனியாகவும் உயிர்க் குறியீடுகளைத் தனித் தனியாகவும் குறியாக்கம் (Encoding) செய்து நிரல் எழுதி அறுவுரை கூறி இணைக்க வேண்டும். உயிர்மெய் போன்ற மீதமுள்ள ஒவ்வொரு எழுத்துக்கும் 8 பிட் கொண்ட 9 பைட் தேவைப்படுகிறது. இணைப்பதிலும் மென்பொருள் சிக்கல் ஏற்பட்டு கணித்திறன் ஆங்கிலம் போன்று இல்லாத நிலை உள்ளது.
(4) நான்காவது சிக்கல்: இஸ்க்கி (ISCII) ஐ 10 பிட் குறியாக்க அலகாக மேம்படுத்தி அனைத்து எழுத்து குறியாக்கம் இல்லாமை.
இஸ்க்கி (ISCII) ஐ 8 பிட் குறியாக்க அலகாக வைத்துள்ளதால் இந்திய மொழிகள் அனைத்து குறியாக்கம் இல்லை. பிரெஞ்சு போன்ற மொழிகள் ஐஎஸ்ஓ (ISO) 8859 வரிசையில் 8 பிட் குறியாக்கத்தில் அனைத்து குறியாக்கம் பெற்றுள்ளன. தேவநாகரி எழுத்துமுறைக்கு அதே 8 பிட் குறியாக்க அலகாக வைத்ததால் அனைத்து எழுத்து குறியாக்கம் இல்லை. அதனால், ஐஎஸ்ஓ (ISO) 8859-12 க்கு ஒ ப்புதல் மறுக்கப்பட்டது. உடனடியாக, இஸ்க்கியை 10 பிட் குறியாக்கத்திற்கு மேம்படுத்தி அனைத்து எழுத்து குறியாக்கம் பெற்று ஐஎஸ்ஓ வின் ஒப்புதலைப் பெற இந்தியா முயற்சி செய்யவில்லை. ஐஎஸ்ஓ இல்லாத போதும் இஸ்க்கியை பின்பற்றி ஒருங்குறி ஒன்றியம் இந்திய மொழிகளை ஒருங்குறியில் சேர்த்துக் கொண்டது. (தமிழ் மொழி தவிர) இதர இந்திய ம ழிகளுக்கு எழுத்துப் பட்டியல் இல்லை. அதனால் அனைத்து எழுத்து குறியாக்கம் வேண்டும் என்று இந்தியா கேட்கவில்லை. இஸ்க்கியையும் மேம்படுத்தி அனைத்து குறியாக்கத்திற்கு அப்போதய இந்திய அரசு வழிவகை செய்யவில்லை.
தமிழ் மொழிக்கு மட்டும் தமிழ்நாடு அரசு ஒருங்குறி ஒன்றியத்தை கலந்தாலோசித்து தனிப்பயன்பாட்டுப் பகுதியில் (Private Use Area – PUA) டாஸ்16 (TACE16) என்ற குறியாக்க முறையை உருவாக்கி பயன்படுத்தி வருகின்றது. எனினும், டாஸ்16 ஐ அடிப்படையாகக் கொண்டு உயிர்மெய் எழுத்துகளுக்கு குறியிடம் கேட்டு ஒருங்குறிக்கு கருத்துரு இதுவரை அனுப்பவில்லை. அதற்கான காரணமும் தெரியவில்லை.
தீர்வுகள்
(1) பிரிக்க இயலாத (அடாமிக் -Atomic) எழுத்துக்கு மட்டும் குறியிடம் ஒதுக்கும் நடைமுறையை கைவிட வேண்டும்.
(2) யூடிஎப்-16 (UTF-16)-ஐ இனி பயன்படுத்த இயலாதபடி தடை செய்து நிறுத்திட (deprecate) வேண்டும்.
(3) யூடிஎப்-10 (UTF-10)-ஐ அறிமுகம் செய்ய வேண்டும்.
(4) தேவை எனில், இஸ்க்கியை (ISCII) 10 பிட் அலகிற்கு மேம்படுத் வேண்டும்.
பிரிக்க இயலாக (அடாமிக் – Atomic) எழுத்துக்கு மட்டும் குறியிடம் என்பதைக் கைவிட்டால், வழக்கில் உள்ள தமிழ் முதலிய மொழிகளில் விடுபட்ட உயிர்மெய் போன்ற எழுத்துகளுக்கு குறியிடம் ஒதுக்கிட வழிவகை ஏற்படும். அனைத்து எழுத்து குறியாக்கம் பெற்று ஆங்கிலம் போன்று கணியத்திறன் இருக்கும்.
யூடிஎப்-16 (UTF-16)ஐ தடை செய்தால் தற்போது முடக்கப்பட்டுள்ள, ஐஈஈஈ (IEEE) உருவாக்கிய தளங்கள் அனைத்தும் மீண்டும் புத்துயிர் பெற்று பிஎம்பீ (BMP) போன்று முழு பயன்பாட்டிற்கு வரும்.
யூடிஎப்-10 (UTF-10)ஐ அறிமுகம் செய்தால் கீழ்க்காணுமாறு குறியாக்க நினைவகம் சிக்கனமாக இருக்கும்.
(1) 000 – 07F > 000xxxxxxx, 1 declet
(2) 080 – 7FFF > 110xxxxxxx, 10xxxxxxxx, > 2 declet
(3) 8000 – 3FFFFF > 1110xxxxxx, 10xxxxxxxx, 10xxxxxxxx, 3 declet
(4) 400000 – FFFFFF > 11110xxxxx, 10xxxxxxxx, 10xxxxxxxx, 10xxxxxxxx, > 4 declet
தேவை எனில், இஸ்க்கியை 10 பிட் குறியாக்க டெக்லட் (Declet) அலகாக மேம்படுத்தி பயன்பாட்டிற்கு கொண்டுவந்த பிறகு ஒருங்குறி ஒன்றியத்தை அணுகி அனைத்து எழுத்துகளுக்கும் குறியிடம் பெற்று அனைத்து எழுத்து குறியாக்கத்திற்கு இந்திய அரசு வழிவகை செய்ய வேண்டும்.
மேற்காணும் சிக்கல்களுக்கான தீர்வுகளை மத்திய மாநில அரசுகள் ஒருங்குறி ஒன்றியத்துடன் இணைந்து செயல்படுத்தினால் தமிழ் முதலிய இந்திய மொழிகள் மட்டுமல்லாமல் சிஜேகே (CJK) போன்ற உலக மொழிகளும் ஆங்கிலம் போன்று கணித்திறன் பெறுவதுடன் குறியாக்க நினைவகமும் சிக்கனமாக இருக்க வழிவகை ஏற்படும்.
உலகம் இன்னும் பல மடங்கு வேகத்துடன் முன்னேறும் வாய்ப்பு உண்டாகும்.
(1) டாஸ்-16 (TACE-16) [Tamil All Character Encoding with 16 bits]
இந்த முறையில் தமிழ் எழுத்துகள் தற்போது உள்ளபடியே இருக்கும். அதாவது, உயிர்மெய் எழுத்துகள் மூவுருவாக (கொ, கோ, கௌ), ஈருருவாக (கா, கெ, கே, கை), சீரற்ற ஓருருவாக (கு, கூ, சு, சூ, டு, டூ போன்று) இருக்கும்.
இது அனைத்து எழுத்து குறியாக்க முறையாகும். தனிப்பயன்பாட்டுப் பகுதியில் (த.ப.ப) [Private Use Area – PUA] அனைத்து எழுத்துக்கும் குறியிடம் கொடுத்து டாஸ்-16 எனும் மென்பொருள் ஏற்கனவே உருவாக்கப்பட்டு பயன்பாட்டில் உள்ளது.
ஆனால், த.ப.ப (PUA) ஒருங்குறி கட்டுப்பாட்டில் இல்லை என்பது கசப்பான உண்மையாகும். தனியாருக்கும், தனியார் நிறுவனங்களுக்கும், த.ப.ப. (PUA) யில் குறியிடம் மட்டும் தனிப்பட்ட பயனுக்காக ஒதுக்கிவிட்டு ஒருங்குறி ஒதுங்கிவிடும். பொறுப்பு எதையும் ஏற்காது.
உலகம் முழுவதும் உள்ள தமிழர்கள் டாஸ்-16 ஐப் பயன்படுத்த அவரவர்கள் டாஸ்-16 மென்பொருளை அவரவர்களே நிறுவிக் கொள்ள வேண்டும். இந்த டாஸ்-16 அடிப்படையில் மறுபடியும் ஒருங்குறியில் பொதுப்பயன்பாட்டுப்பகுதி (GUA General Use Area) யில் 300 மேற்பட்ட எழுத்துக்கு குறியிடம் கேட்டுப் பெற்றால் தான் 100% கணியத் திறன் பெற இயலும்.
ஆனால், BMP GUA – யில் குறியிடங்கள் காலியாக இல்லை என்பதால் இந்த டாஸ்-16 மென் பொருளால் குறிப்பிட்ட சிலரைத்தவிர, பொதுமக்களுக்கு பயன் படாது. அதனால், டாஸ்-16 கைவிட்டுவிடலாம்.
(2) தமிழ் நவீன எழுத்து முறை (Tamil Modern Script)
இதுவும் அனைத்து எழுத்து குறியாக்க முறையாகும். இந்த முறையில் தமிழ் எழுத்துகள் தற்போதுள்ளபடி இருக்காது. அனைத்தும் சீரான ஓருருவாக இருக்கும். இந்த தமிழ் நவீன எழுத்து முறை அடிப்படையில் பொதுப்பயன்பாட்டு ப்பகுதி (GUA General Use Area) யில் 300 மேற்பட்ட எழுத்துக்கு குறியிடம் ஒருங்குறியில் கேட்டுப் பெற்றால் தான் 100% கணியத் திறன் பெற இயலும். ஆனால், BMP GUA – யில் குறியிடங்கள் காலியாக இல்லை என்பதால் இந்த நவீன எழுத்து முறை பயன்படாது. ஆக, இதனையும் கைவிட்டுவிடலாம்.
(3) இடை உயிர் எழுத்து முறை (Medial Vowel Method)
இந்த முறையில் உயிர்க் குறியீடுகளுக்கு மாற்றாக இடை உயிர் எழுத்தை அறிமுகம் செய்து பயன்படுத்த வேண்டும்.
தொல்கப்பியரின் “மெய்யின் வழியது உயிர் நிலை” என்பதை பின்பற்றி “ஆ” முதல் “ஔ” வரை இடை உயிர் எழுத்து யாவும் “புள்ளி இல்லா” மெய்யின் வலப்புறம் அமையும்.
இந்த இடை உயிர் எழுத்தின் வரி வடிவத்தை தமிழக அரசு இறுதி செய்ய நிபுணர் குழுவை அமைக்க வேண்டும்.
மாதிரி வரி வடிவங்கள் தொடுப்பில்:
https://drive.google.com/file/d/0BzyrEHRUOQIIY09OejhhOUtyU0FtNmxTSDRURUUySldlb3hv/view?usp=drivesdk
தொல்கப்பியரின் “மெய்யின் இயற்கை புள்ளியொடு நிலையல்” என்பதை பின்பற்றி மெய் எழுத்துகள் புள்ளியுடன் அமையும்.
இந்த முறையின் சிறப்பு “உயிர் மெய் எழுத்துக்கு தனியாக குறியிடம் வேண்டியதில்லை”. 100% கணியத் திறன் பெறுவது உறுதி. அதுபோல், தமிழ் நிரல் மொழி ஆவதும் உறுதி. இனி, தமிழ் “அசை மொழி” (Syllabary Language) எனும் வகைப் பாட்டில் இருந்து விடுதலை கிடைக்கும். இனி, தமிழும், ஆங்கிலம் போல், எழுத்து மொழி வகைபாட்டில் இடம் பெறும் – உச்சரிப்புக் குறைபாடு இல்லாமல்